奇偶校验
校验位只有一位,根据编码长度中1的个数来确定这1位的数值
有两种校验方法:奇校验和偶校验,实际上是根据看奇数为1还是偶数为1,可以在接收端模2来校验
奇校验:原始码流+校验位 总共有奇数个1
偶校验:原始码流+校验位 总共有偶数个1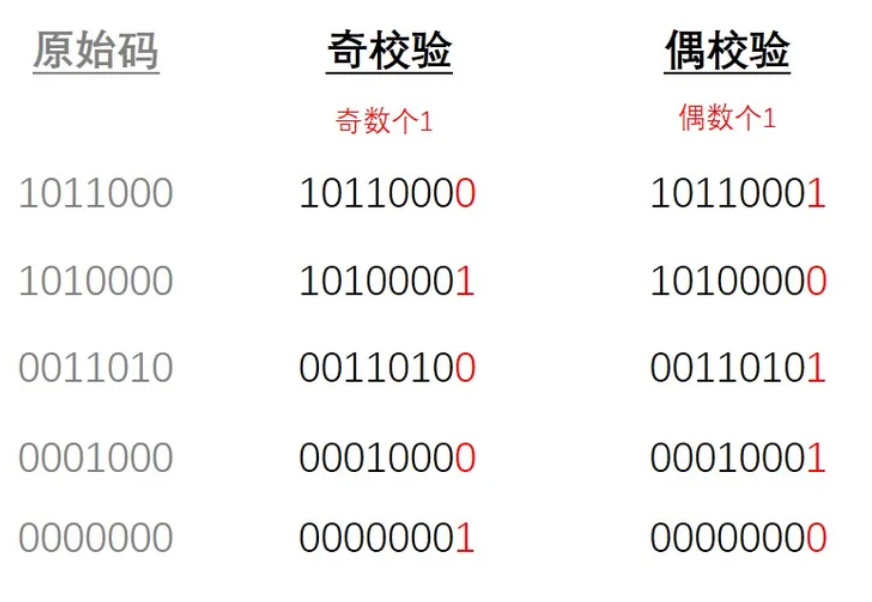
数学原理
编码的数学推导
模2除法
无进位的相加/无进位的相减/异或这些说的都是一个东西,以4bit长度为例
1 | 1101 |
模2除法就是二进制除法,但是在相减时采用无进制相减

多项式代数和多项式除法
高等代数中的多项式代数知识
1 | M/N=Q...R |
这里容易得到,R会比N幂次要低,就和整数除法m/n=q..r ,0<=r<n 一样
- 除法规则-竖式除法
每次消去余数最高项,直到余数最高次项小于除数
!除法
{kind=link}
编码算法
将二进制看成多项式,这里是整个crc想法来源.
比如
1101可以看成
设校验码+原信息长度共n位,其中校验码长度为k.在msg长度为n位的前提下,介绍一个除式,记作G(x),其最高项次数为k,并记原信息叫做S(x),最高项次数为n-k-1.
则根据多项式的带余除法,知一定存在一对唯一的P(x)和R(x)使得
此时再令
于是当接收端收到数据后,再做
模2带余除法存在性和唯一性
存在性
因为与普通带余除法每区别,不管是无进位相减还是带进位相减,最终都会得到一个结果,故存在性比较显然
唯一性
设另外存在P(x)和T(x),也满足条件.则有
注意这里用的是模2加减法
能检测哪些错误
这里最主要的是一个建模,核心在这里。是沟通理论和实际的桥梁。接下来就是理论上的证明了.所以我们思考问题的时候,是需要去寻找理论中的概念和原理,并将其和实际对应起来.对于包含错误的bit流可以看成
如果
当余数为0等价于E(x)为0 …(命题1)
E(x)不为0时等价余数不为0 …(命题2)
解释:余数为0也可能是G(x)整除E(x).命题1和命题2也是等价的
定理1
如果G(x)至少有2项,则可以检测出所有的单bit错误
证明: 单bit错误表示
定理2
如果
证明:假定通过G(x)生成的编码信息为F(x),
则
其中
令x=1可得
故F(1)一定是偶数,F(x)又是多项式,故F(x)一定有偶数项.所以当发生奇数个错误时余式一定不为0.命题2成立
剩下的定理
原论文中总共给出了8条定理,目前水平有限,等待后续领悟。
原论文
原论文是大牛Peterson在1961年发布的论文Cyclic Code for Error Detection.
crc碰撞
这里介绍2个单词,在编码领域会经常要讨论的一个问题.冲突概率conflict collisions.我之前其实一直想不通,既然会有概率冲突,为啥还可以用来做校验呢?
后面我想明白了,加密安全和传输校验不一样,信息传输过程中即使碰到了冲突也是可以接受的,接收端就认为这是源端发送的数据。但是当校验错误,接收端就要求源端重新发送。还有一个特性就是,信道一般发生错误集中在某一段内,不会产生各种各样的花式错误.
就像md5一样,虽然大家一直在用,但md5也会有冲突,愿意使用就表示接受冲突带来的结果。md5由我国的王小云院士优化了破解算法md5冲突王院士,感兴趣的同学可以看下王院士的主页.
碰撞分析
这块涉及到比较复杂的数学知识,留作自己后续的研究方向.
常用的除数多项式
所以检测错误的能力和选择多项式的特性有关,不是随便瞎选的
见wiki常用的多项式
算法实现
朴素的竖式多项式除法的翻译
这里主要思路是用商消去最高位,然后在输入的数组上减去商*生成多项式,因此余数也是保存在输入的被除多项式位置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32int divide( double num[], int nlen,
double den[], int dlen,
double quotient[], int *qlen )
{
int n, d, q;
// The lengths are one more than the last index; decrement them
// here so the call is less confusing
nlen--;
dlen--;
q = 0;
// when n > dlen, the result is no longer a polynomial
// (e.g. trying to divide x by x^2)
for ( n = nlen; n >= dlen; n-- )
{
// First, divide the nth element of numerator with the last element
// of the denominator
quotient[ n - dlen ] = num[ n ] / den[ dlen ];
q++;
// Now, multiply each element of the denominator by each
// corresponding element of the numerator and subtract the
// result
for ( d = dlen; d >= 0; d-- )
{
num[ n - ( dlen - d ) ] -= den[ d ] * quotient[ n - dlen ];
//采用模2除法,需要修改成这行代码
num[ n - ( denlen - d ) ] = fabs( num[ n - ( denlen - d ) ] );
}
}
*qlen = q;
return ( nlen - *qlen + 1 );
}使用异或来计算
这里比较难理解,让我想了很久,还是基于竖式除法的思路,从竖式除法我们可以发现,32位的生成多项式最高位可以不存储,因为每次都是消去最高项;可以用一个32位int来保存余数,长度小于32位的二进制序列余数就是它自己,因此需要在右端补上32位;从竖式除法中我们可以发现,做减法的次数等于被除数长度-除数长度+1;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24unsigned long int compute_crc( unsigned long input,
int len,
unsigned long divisor )
{
//要做被除数长度-除数长度+1=24+32-33+1=24
while ( len-- )
{
//如果最高位是1,那么这位是要被消去,余数等于剩下的和除数异或;如果最高位是0,我们发现最高位死0,实际上是
//商为0,和全0异或等于它自己,等效于直接左移
input = ( input & 0x80000000 ) ? divisor ^ ( input << 1 ) : ( input << 1 );
}
//余数存储在32位,这里实际上等价于竖式多项式的低32位;因为运算过程中,余数始终保存在input位置
return input;
}
...
unsigned long int crc32_divisor = 0x04C11DB7;
//下面的input按ABC实际上的值字节做了反转,多项式是低字节在低位,为了位对齐
// 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, // C
// 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, // B
// 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0 // A
unsigned long int input = 0x8242C200; // ABC; backwards & left aligned
printf( "%lx\n", compute_crc( input, 24, crc32_divisor ); // 5A5B433A
crc查表法
https://www.cnblogs.com/esestt/archive/2007/08/09/848856.html
常见组件关于crc的实现
- mariadb中用的是查表,或者使用cpu的sse来计算
mariadb crc - gcc中zlib
gcc中zlib