面向对象的软件设计方式
大型软件工程中是根据需求中的实体来建模的,对象往往代表了这些实体。具有这些实体的属性,并以提供和其他对象交互的函数。有以下的优势:
- 逻辑容易设计和理解
- 可以提高代码功能逻辑的复用
- 代码上高内聚低耦合,面向接口依赖
- 提供了运行时的动态绑定
面向对象的基本概念和模式
类:类是描述一类对象的特征和提供特定功能的代码实体,同时也是实例的模板,实例以类为模板
实例: 具体的一个对象,具有实例变量,是类的一个具体化。
类有静态属性和动态属性之分,静态属性是所有实例共享的,动态属性是每个实例特有的,又称实例属性
举个例子,以人为例
1 | usingnamespace std::string; |
来验证前面的理论,类是实体的建模,成员是对实体属性的抽象。两个实例zhangsan和lisi是类Person的具体化,动态属性的值各不相同。但都有一个共享的静态变量。类有特定功能的函数或者说有特定行为的函数,这些函数用来和其他对象交互.
进一步的概念
经过上面的例子,就可以归纳出在代码实体上的概念:
- 成员变量,类的属性
- 方法,类的特定行为的函数
- 成员变量和方法的权限
- 普通函数,和c中函数类似,不在类的代码块内部
- 构造函数和析构函数
- 继承,对象的树级关系
- 虚函数,子类可以重写的方法,编译器用virtual关键字来识别
- 纯虚函数,用来定义接口,带有纯虚函数的不能实例化,编译器用virtual关键字+方法体=0来定义
- 抽象基类,用做接口定义,包含纯虚函数的类是抽象基类,不能实例化,只能被继承,实例化成他的子类
类型兼容原则
所指的替代包括以下情况:
- 子类对象可以当作父类对象使用
- 子类对象可以直接赋值给父类对象
- 子类对象可以直接初始化父类对象
- 父类指针可以直接指向子类对象
- 父类引用可以直接引用子类对象
下面介绍构造函数和析构函数
默认构造函数和无参构造函数
默认构造函数是创建对象时默认调用的,如果没有声明,则编译器会按照一定条件来默认创建一个无参的构造函数,当然自己也可以声明无参的。自己声明了,编译器则不会再创建。编译器创建的构造函数并不会赋初始值。编译器的创建策略主要是
- 有非基本类型的成员(自定义类型或者string类型),并且这些成员本身有默认构造函数。这种情况是如果只有基本类型在拷贝对象时,直接拷贝内存块即可
- 有虚函数和虚继承,这种情况是需要虚函数表
- 继承的父类有默认构造函数
这里推荐一个网站,可以用来查看编译后的汇编代码。https://godbolt.org/
引用1中的结论我是验证过的,在gcc13.2上。记住要加-O0(减号大o后面跟个优化等级)才可以得到结果
- 如果自己只定义了默认构造函数,编译器是否会生成拷贝/赋值/移动构造函数?
如果程序中有用到对象拷贝赋值则会生成并调用默认的构造函数,没有用到则不会生成 - 如果只定义了拷贝构造函数,还会生成默认构造函数吗?
这种不会,编译会报错
析构函数
在释放对象时,编译调用的函数。如果是用来继承的类,必须声明为虚函数
父子类的构造函数和析构函数顺序
构造:先基类,再子类
析构:先子类,再基类
对上面继承时析构函数需要声明为虚函数做些说明,因为虚函数再调用时才会根据运行时状态,调用子类对象的析构函数。编译器又会自动释放基类,从而可以完整的释放这条继承链上的所有对象。不是虚函数的话,会直接调用基类的析构函数,发生内存泄露
拷贝构造函数
形如下面的code
1 | //调用拷贝构造生成对象 |
拷贝构造是一定会生成新对象的,可能是临时的,过一会被删除。这也解释了为啥函数参数推荐使用引用或者指针,避免了重复创建临时对象。
关于函数的2种情况实际上可以统一,从程序的内存布局来理解,都是在调用者和被调用者栈帧之间拷贝对象,因为栈帧内的内存会用完就被释放。
赋值运算符
形如下面的code
1 | A a; |
赋值号左右两边都是已经存在的对象,不会产生新对象
移动构造函数
这个函数还是为了减少内存拷贝带来的特性。在编程中,有些类中会包含大的成员数组,或者大的成员变量。如果在拷贝赋值时可以直接将这个大的成员
直接移动给目标对象,可以减少很多拷贝开销。语义上理解很像是移动或者所有权转移。那怎么去实现他呢?需要一种标志来表示程序员啥时候可以使用移动语义,现在的引用是无法转移的。于是,那些C++大牛们提出了一个另外一种引用,当参数中以这种形式的引用出现时,编译器就会按照移动语义来实现。
一般文献中会称为右值引用,就可以理解为一种引用,不过是用来标志支持移动语义的。左值和右值可以相互转换
1 | A (A&& other){ |
移动运算符
和上面类似的,运算符两边都是已经存在的对象,并且是移动语义
注意 拷贝构造/拷贝赋值与移动构造和移动赋值如果自己提供了其中一个,则编译不会提供另一个。因为只要有一种就都可以编译通过。可通过=default来声明
前面的测试代码见https://github.com/dingweiqings/study/tree/master/cpp_study/src/construct
汇编验证
1 | #include<iostream> |
将上面代码拷贝到https://godbolt.org/
C++的对象模型
面向对象的语言都需要解决下面几个问题:
- 对象的成员数据存储和访问
- 对象的成员函数存储和访问
- 对象的静态成员和方法的存储的访问
- 在有继承的情况下,前面1,2,3怎么处理
- 对于多态的运行时绑定策略
- 对象的创建和释放
几种可能的实现
- 简单对象模型
暴力一点,对每个实例,都把成员数据和成员函数都都拷贝一份,这样不就都可以访问到了吗?静态成员还是要单独存储。
继承把父类的成员数据和函数都拷贝一份,因为每个实例有自己独立的拷贝,所以多态是自然支持的 - 基于表格的模型
第一种的内存消耗太大,虽然访问都是固定时间.于是,我们产生了第二种想法,可以将成员函数和成员数据分开来存储。把成员函数放入一个表格之中,这样成员函数就可以被所有实例共享。成员数据还是随每个实例存储,每个成员额外增加一个指向成员函数表格的指针。想法是根据成员函数有共享性,成员数据是独立性。这里先记住2个名字,函数表指针和函数表
C++的成员变量存储和访问
静态变量和静态函数
静态变量是转变成global变量,但会由编译器控制可见性。就类似于普通定义的全局变量.所以访问也是和普通变量类似,通过地址直接访问
无继承的情况
类似于c结构体的存储,按照声明变量的顺序和大小,从低地址到高地址存储。当然中间可能会由于体系结构要求的对齐。这里C++并未规定,变量必须连续存储,只要按照变量声明的顺序即可。也就是说,可以在成员变量缝隙间插入特定的内容.详细可见《深入探索对象模型》的第3章3.2节
1 | class A{ |
先忽略虚函数表的内容,后面会再介绍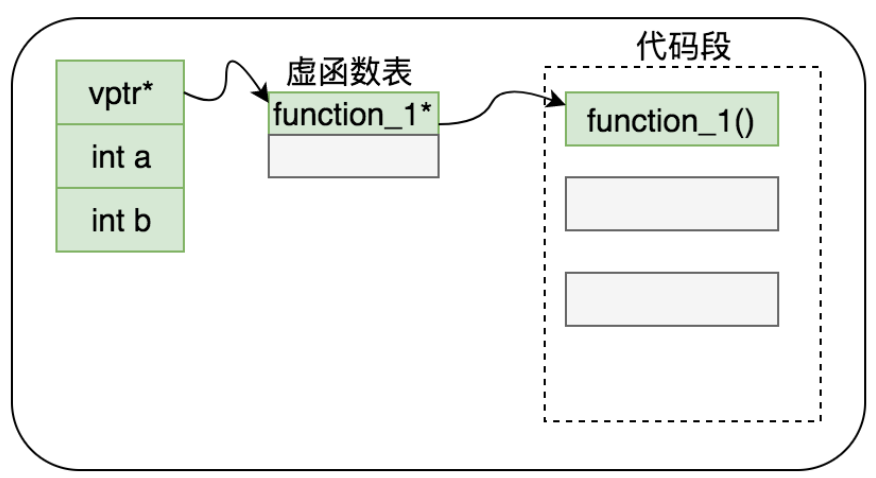
单一继承的情况
子类会将父类实例成员拷贝一份.类似于包馅饼。因为这样才可以完整的实现多态,否则向上转型取字段就不对了。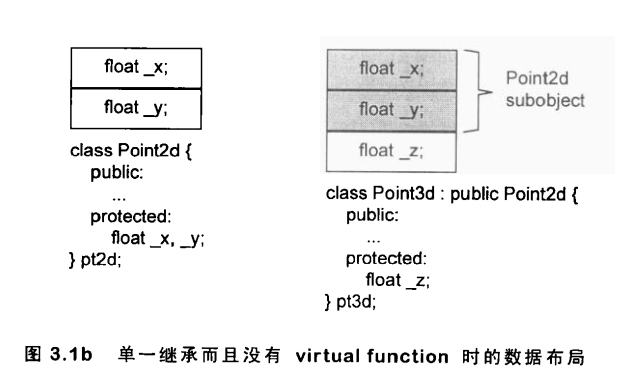
多重继承(继承树上无重复)
就包多次馅饼,从小到大包.
所以此时,如果有重名变量和方法,需要明确指定基类.比如:
两个基类中有重名的方法和变量,SetWeight,则需要用完全限定名称
1 | SleepSofa a; |
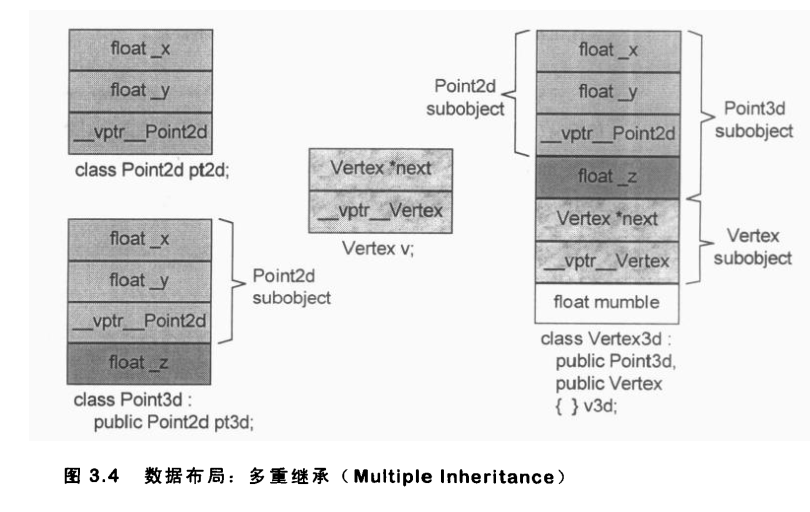
多重继承(继承树上有重复)
这种情况,如果还是包馅饼,对于继承树上重复出现会被多个子节点包进去,造成内存的浪费,也会导致访问和修改的歧义。C++大佬们又想了个办法,(后面你会发现和虚函数的处理策略是类似的).增加了共享继承的机制,用现有的关键字virtual,语义同虚函数相同。在类对象中增加一个虚基类指针,用以指向虚基类在实例中的偏移量。
虚基类指针在内存中放在哪里呢?有2种放置策略
- 将所有虚继承的父类都搞一个指针放在实例中,指向基类在实例中的内存位置,以用来访问成员。这种每个实例都有额外的指针存储,在基类很多的情况下,开销较大
- 多个虚继承的父类就搞一个虚继承表(和虚函数表很像),指代基类在实例中的偏移量。由于类的布局是固定的,所以只需要准备一份这个表即可。(根据候捷大佬《深入探索C++模型》原文中说微软编译器是这样做的)
- 和虚函数表放在一起,gcc和clang是这样做的,下面会详细分析gcc的虚函数表
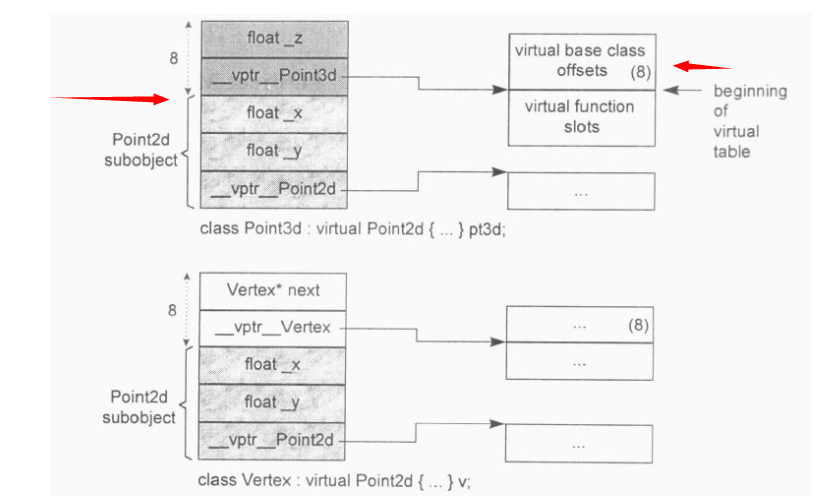
C++的成员函数存储和调用
静态函数
静态函数就是只能访问静态变量的函数,除此之外函数的存储和调用和其他成员函数无区别,静态函数不能是虚函数,编译期就可以得到地址.
继承树中所有类都无虚函数
这种和普通非成员函数调用无区别,编译期就可以确定
虚函数
无继承
编译器会创建一个虚函数表,在实例中增加一个隐藏成员,这个成员指向虚函数表的位置
1 | class Base { |
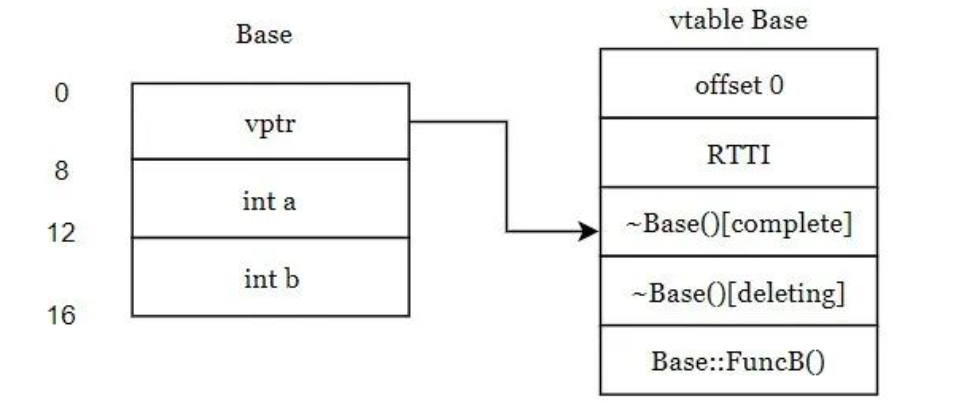
注意 详细介绍一下虚函数表中的概念,
- 整个虚函数表,是一个数组,每一项8字节(64位架构下)固定长度,所以可以按照偏移量来索引
- function pointer 存储虚函数的区域,每一项都是一个内存地址,指向函数的入口,按照源码顺序来排列
- virtual base offset 虚函数表中有些项存储的是虚基类的偏移量
- offset to top 这种项记录的是和当前实际类型的开头的偏移量
下面给出一个简单vtable例子,有个简单的印象1
2
3
4
5Vtable for A
A::vtable for A: 3 entries
0 (int (*)(...))0
8 (int (*)(...))(& typeinfo for A)
16 (int (*)(...))A::af
单继承的情况(这种很重要,平常用的最多,而且是理解后续模型的基础)
1 | class Base { |
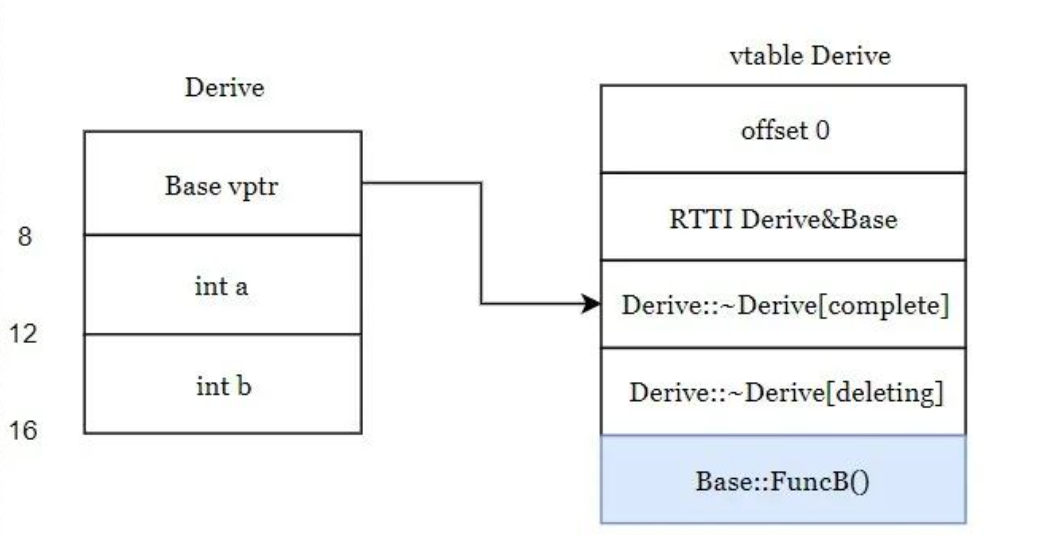
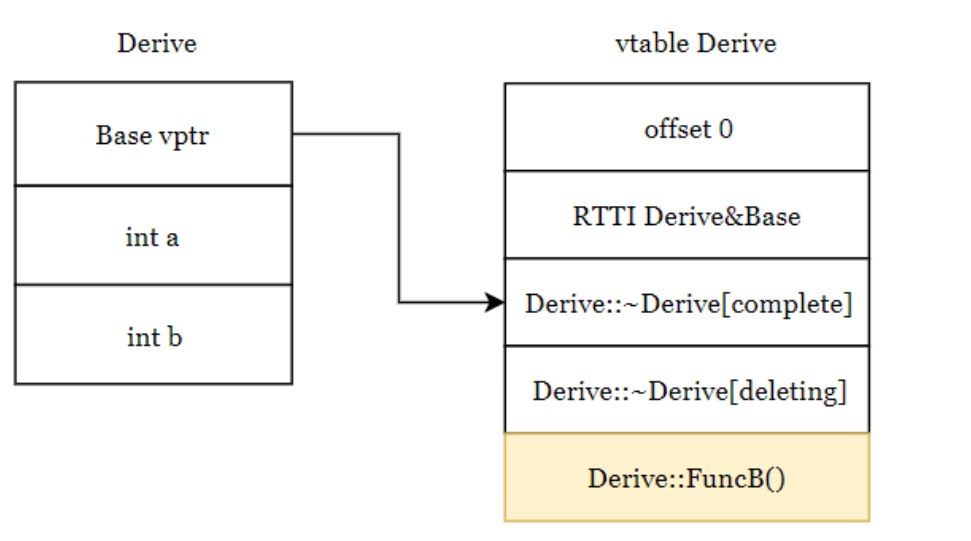
注意 这里可以发现,父类的vptr指针指向的也是子类的vtable.如果子类有覆盖父类的方法,虚函数表中就填子类的,如果没有就把父类的拷贝过来.每个类都有自己的虚函数表,并不是通过共享虚函数表来实现继承的.
多重继承
这种是每个继承树上的每一个类在实例内存中指向自己类的function pointer,这样在调用基类虚函数时,会查找到实际类型的函数地址,从而实现多态
下面会详细介绍如果根据虚函数表查找实际类型的函数地址
注意 这里有个主基类的说法,编译器会在继承的父类中找一个有虚方法的父类,复用他的vptr,在调用主基类的方法时不需要调整this指针。下面虚函数表的会详细解释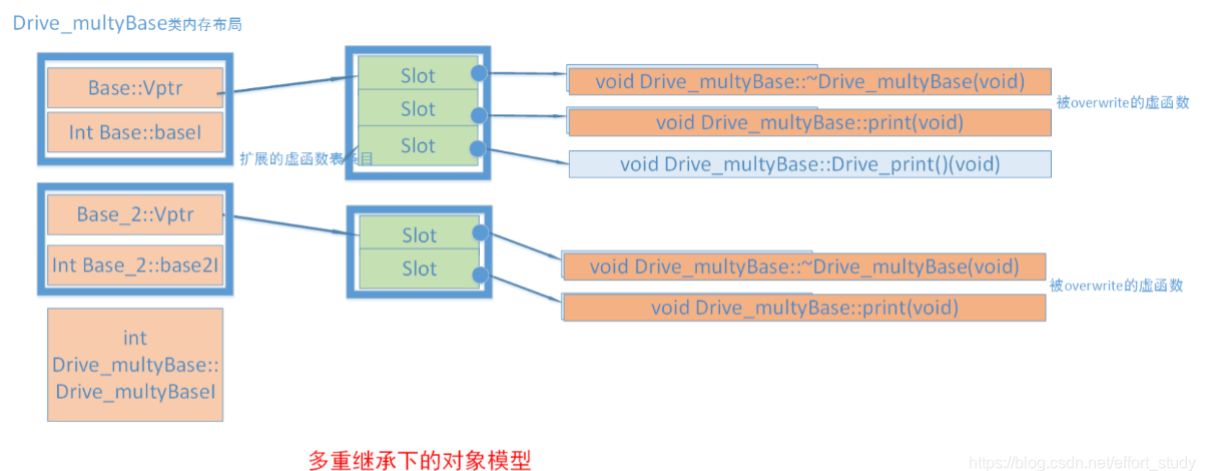
虚继承
在继承树上有重复类的时候,根据前面对象数据成员内存布局,需要添加一个基类的偏移量来表示每个基类在实例中的内存位置.gcc是把基类指针放在虚函数表中,下面会详细介绍虚函数表
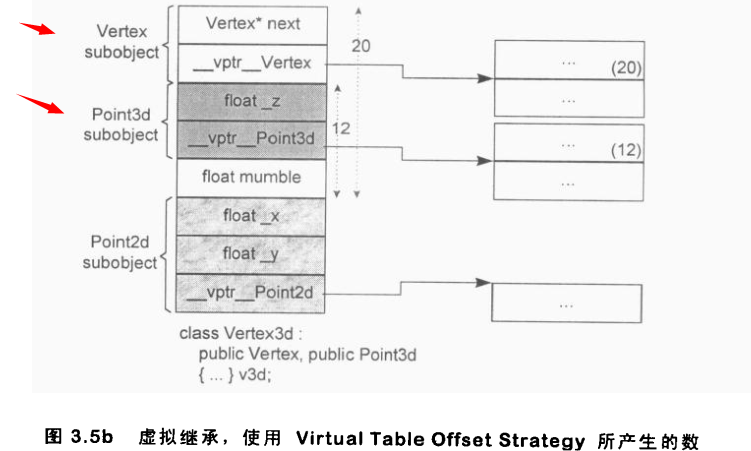
虚函数表
这些内容比较复杂,另起一篇文章
gcc的虚函数表
gcc查看虚函数表
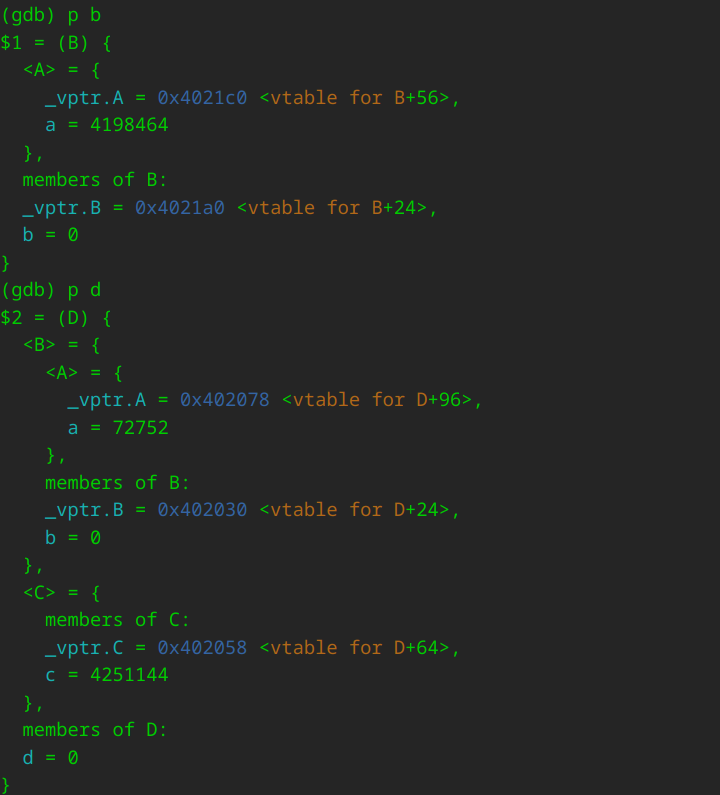
gdb打印对象内存布局
gdb命令
每行打印一个结构体成员
可以执行set print pretty on命令,这样每行只会显示结构体的一名成员,而且还会根据成员的定义层次进行缩进按照派生类打印对象
set print object on查看虚函数表
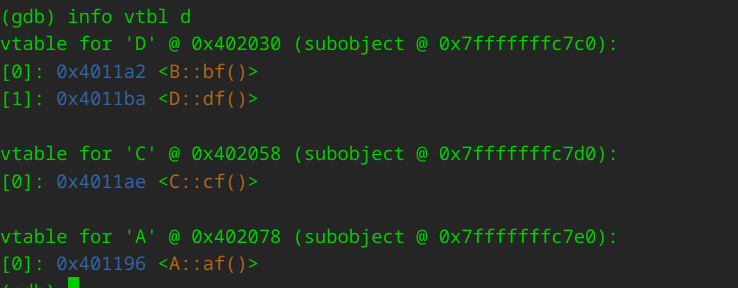
通过如下设置:set print vtbl on
之后执行如下命令查看虚函数表:info vtbl 对象或者info vtbl 指针或引用所指向或绑定的对象
- c++名称转换
GNU提供的从name mangling后的名字来找原函数的方法,c++filt工具,执行c++filt _ZTV1A
在线反修饰名称的网站http://demangler.com/
汇编查看实例函数调用
汇编中会额外增加一个this指针,一般是放在rdi寄存器中
总结
基本要解决的问题是下面几个?
- 如何保证子类可以继承父类的成员和非虚方法?这两种是编译期就可以决定访问地址的,主要思想是包馅饼,vtable和成员都是类似的思想
- 如何保证子类调用自己重载的虚方法?每个基类都有一个指针,指向子类的vtable,并在调用非主要基类的子类方法时调整this指针
补充
MSVC ABI和Itanium ABI(gcc和clang遵循这个标准)
C++ Itanium ABI 主要分为四大板块:
指导程序中的各种数据结构如何正确而一致地在内存中布局(Data Layout);
指导在二进制层面如何调用其他函数(调用约定,Calling Convention);
为 C++ 的异常处理机制提供正确的实现(Exception Handling);
定义输入到链接器的对象文件的格式(Linkage & Object Files)