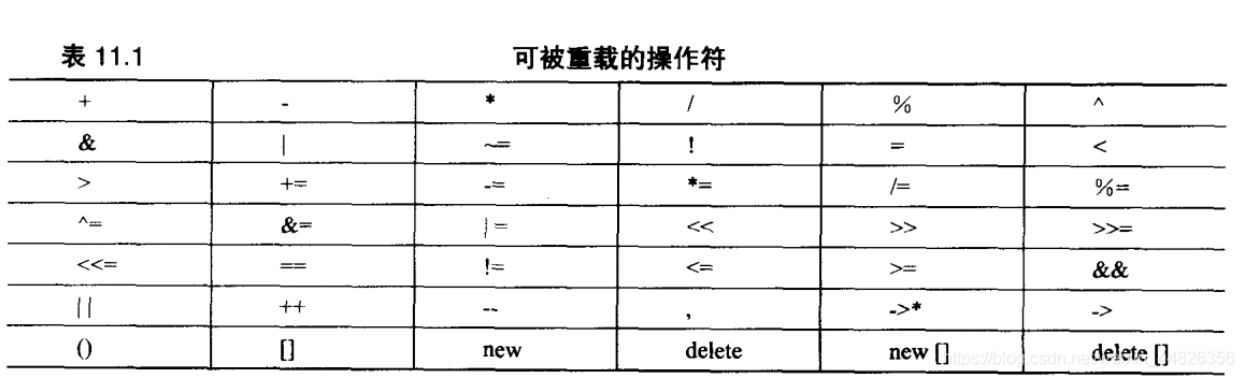
简单介绍下编译原理 词法分析->语法分析->生成中间代码->机器无关的优化->生成汇编(机器相关的优化)->交给汇编器生成机器码
词法分析 token 解析字符串流,确定一个个的token,比如在c语言中,确定是if,while这些关键字还是变量名,运算符等.最终会生成符号表。
词法框架 根据正则表达式来定义某种特定token的规则,在解析字符串流的时候,根据正则来判断属于哪种token
常见的词法框架/工具 lex/flex,是通过正则表达式和自定义解析字符串综合工作的
语法分析 主要在于如何表达语法规则和检验语法规则.
语法规则 编译器大佬提出了一种文法,只关注字符串的变换.并定义终结符号和非终结符号的概念.非终结符号则可以继续产生新符号,从而用字符串实体表达出了语言的语法规则.非终结符号到另外一个符号串叫做产生式.
产生式 比如程序一开始会有一个非终结符号S,对于C语言这个语法来说,会有下面的产生式.下面给出部分产生式做说明
1 2 3 4 5 6 7 S -> void main(){B} B -> Y; Y -> Y;STATEMENT | e STATEMENT -> D | A | BLOCK D -> TYPE id | TYPE* id BLOCK -> IF(C){B} ELSE{B} | while(C){B} A -> id + id | id -id | id * id | id /id
解释一下上面的产生式,id和e,type这些是终结符.
语法分析的实现 给定一组字符串可以是递归去判断,看最终会不会达到终结符,然后比对终结符是否和字符串中的相同.但在实际中采用的是更有效率的DFA表格,预先对产生式处理,然后可以对扫一遍字符串就可以判定是否合法,并构建出语法树
语法树 TODO,这块我目前还没搞懂
语法分析框架 好在大佬们已经写出来好的工具来给咱们使用了.yacc是语法分析的一种实现,根据用户定义的语法规则,做对应的动作.所有的查询引擎都有这个模块,比如mysql,prometheus.根据不同语言的yacc(c语言),javacc还有goyacc
goyacc做一个简单的计算器 我们来2步走,主要是这2个方法
1 2 3 4 5 6 7 8 9 type exprLexer interface { Lex(lval *exprSymType) int Error(s string) } type exprParser interface { Parse(exprLexer) int Lookahead() int }
expr函数前缀,goyacc中可以自定义. 在自己的app中可以直接调用Parser来分析。但要提供lex的实现.下面实例中就可以看到
分析词法 细心的同学就会发现,这里实际上实现了上面lexer的2个接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 func (x *exprLex) Lex(yylval *exprSymType) int { for { c, _, err := x.input.ReadRune() if err != nil { return eof } switch c { case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9': return x.num(c, yylval) case '+', '-', '*', '/', '(', ')': return int(c) case '×': return '*' case '÷': return '/' case ' ', '\t', '\n', '\r': default: log.Printf("unrecognized character %q", c) } } } // Lex a number. func (x *exprLex) num(c rune, yylval *exprSymType) int { var b bytes.Buffer b.WriteRune(c) L: for { c, _, err := x.input.ReadRune() if err != nil { return eof } switch c { case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '.', 'e', 'E': b.WriteRune(c) default: _ = x.input.UnreadRune() break L } } yylval.num = &big.Float{} _, ok := yylval.num.SetString(b.String()) if !ok { log.Printf("bad number %q", b.String()) return eof } return NUM } func (x *exprLex) Error(s string) { log.Println("parse error: ", s) }
分析语法 产生式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 %{ package main import ( "fmt" "math/big" ) %} %union { num *big.Float } %type <num> expr expr1 expr2 expr3 // 定义在后面的符号比定义在前面的符号具有更好的优先级 %token '+' '-' '*' '/' '(' ')' %token <num> NUM %% top: expr { if $1.IsInt() { fmt.Println($1.String()) } else { fmt.Println($1.String()) } } expr: expr1 {} | '+' expr { $$ = $2 } | '-' expr { $$ = $2.Neg($2) } ; expr1: expr2 {} | expr1 '+' expr2 { $$ = $1.Add($1, $3) } | expr1 '-' expr2 { $$ = $1.Sub($1, $3) } ; expr2: expr3 {} | expr2 '*' expr3 { $$ = $1.Mul($1, $3) } | expr2 '/' expr3 { $$ = $1.Quo($1, $3) } ; expr3: NUM | '(' expr ')' { $$ = $2 } %%
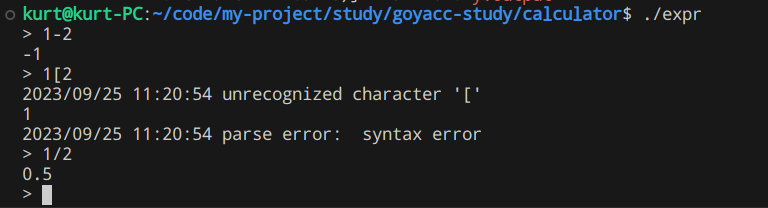
应用中如何调用分析器 读取命令行的输入,并调用分析器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func main() { in := bufio.NewReader(os.Stdin) a := big.Float{} a.String() for { if _, err := os.Stdout.WriteString("> "); err != nil { log.Println("WriteString: ", err) } line, err := in.ReadBytes('\n') if err == io.EOF { return } if err != nil { log.Fatalf("ReadBytes: %s", err) } //调用分析器 exprParse(newExprLex(line)) } }
运行 安装 go install golang.org/x/tools/cmd/goyacc@latest
goyacc使用 Usage of goyacc:
构建 go build expr.go lexer.go main.go
执行
goyacc 做json parser 最主要是整理出json的产生式,然后理解下yacc框架下的整体工作流程,就可以搞出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 %{ package jsonparser type pair struct { key string val interface{} } func setResult(l yyLexer, v map[string]interface{}) { l.(*lex).result = v } %} %union{ obj map[string]interface{} list []interface{} pair pair val interface{} } %token LexError %token <val> String Number Literal %type <obj> object members %type <pair> pair %type <val> array %type <list> elements %type <val> value %start object %% object: '{' members '}' { $$=$2 setResult(yylex, $$) } members: { $$ = map[string]interface{}{} } | pair { $$ = map[string]interface{}{$1.key: $1.val} } | members ',' pair { $1[$3.key] = $3.val $$ = $1 } pair: String ':' value { $$ = pair{key: $1.(string), val: $3} } array: '[' elements ']' { $$ = $2 } elements: { $$=[]interface{}{} } | value { $$=[]interface{}{$1} } | elements ',' value { $$=append($1, $3) } value: String | Number | Literal | object { $$ = $1 } | array
测试代码见 https://github.com/dingweiqings/study/tree/master/goyacc-study
引用
龙书 编译原理
yacc使用